solr8.20用法
前言
Solr是一个基于Lucene的Java搜索引擎服务器。Solr 提供了层面搜索、命中醒目显示并且
支持多种输出格式(包括 XML/XSLT 和 JSON 格式)。它易于安装和配置,而且附带了一个基于 HTTP 的管理界面。Solr已经在众多大型的网站中使用,较为成熟和稳定。Solr 包装并扩展了 Lucene,所以Solr的基本上沿用了Lucene的相关术语。更重要的是,Solr 创建的索引与Lucene 搜索引擎库完全兼容。通过对 Solr 进行适当的配置,某些情况下可能需要进行编码,Solr 可以阅读和使用构建到其他 Lucene 应用程序中的索引。此外,很多 Lucene 工具(如Nutch、 Luke)也可以使用 Solr 创建的索引。
solr部署
在新版solr5.x以上版本中已经没有了solr.war的存在。不过在server依然有solr提供的webapp文件夹可以提供在Tomcat下部署。
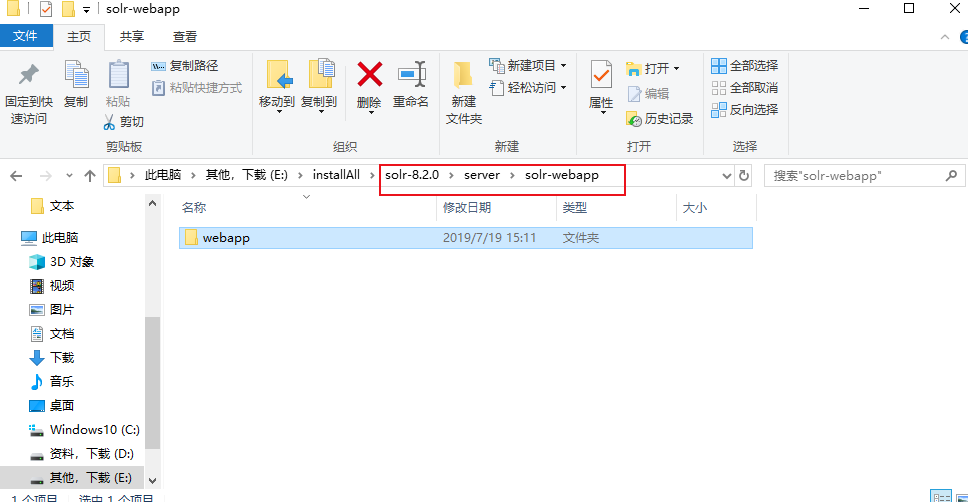
在5.x以上版本中的变动中solr有了独立的服务器-(server-solr)
solr环境搭建
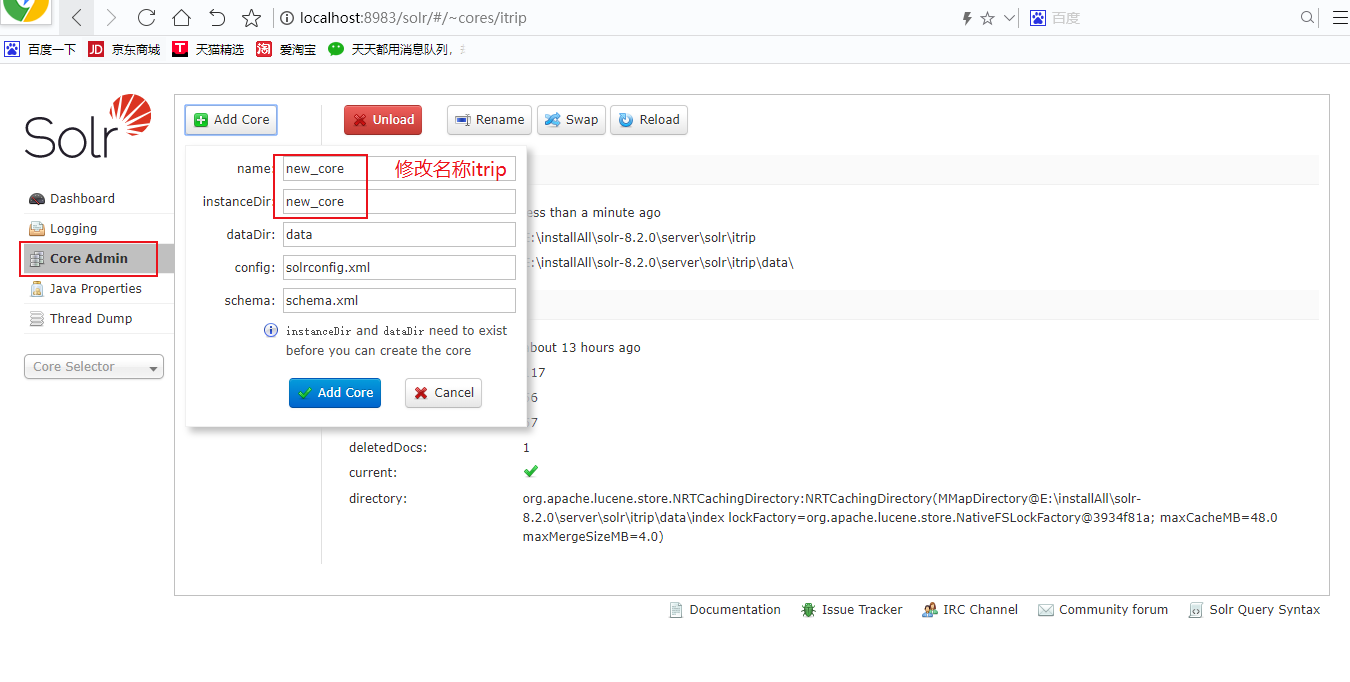
server/solr下创建一个文件夹如:”itrip”
复制server/solr/configsets/_default下的文件到新建文件夹中”itrip”
cmd - 切换到solr/bin目录下 - solr.cmd start 启动solr,浏览器输入localhost:8983/solr启动控制台
进入Core Admin创建”itrip” core
在itrip的文件夹中会生成一些新的文件,最后的格式
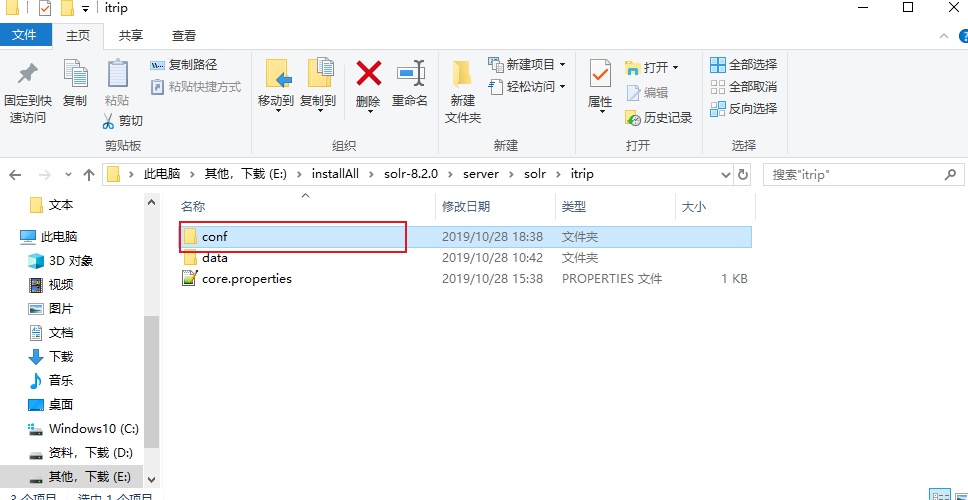
进入itrip下的core.properties文件添加 name=itrip
solr引入数据
在solr每一个core存放着一份文件每一份文件中都是一次在数据库中查询出的数据。以之前创建的itrip为例
将mysql连接jar、solr8.2/dist文件下的solr-dataimporthandler-8.2.0.jar和solr-dataimporthandler-extras-8.2.0.jar两个jar放入server/solr-webapp/webapp/WEB-INF/lib下
在itrip中的conf文件中打开solrconfig.xml找到节点中存在name=”/select”位置在它之前创建节点指向连接数据库的xml
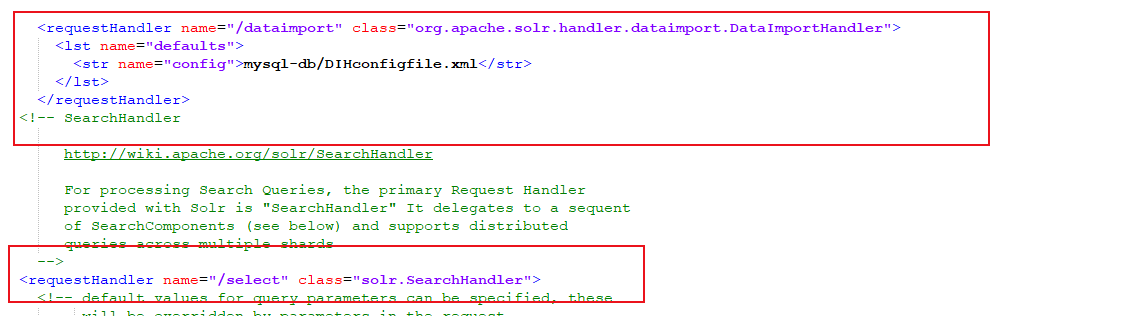
itrip/conf文件夹下新建mysql-db/DIHconfigfile.xml
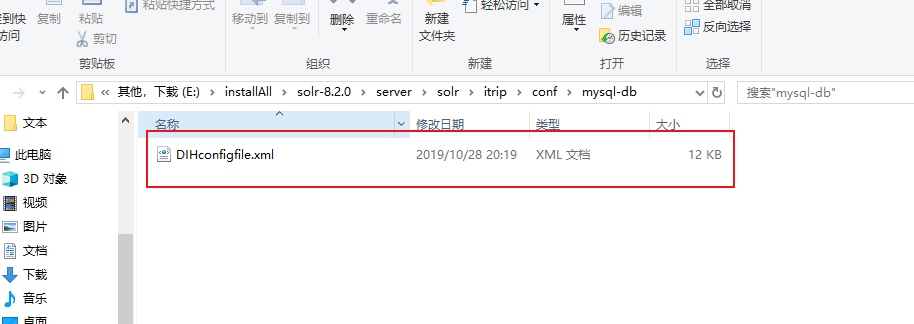
配置DIHconfigfile.xml
<dataConfig> <dataSource type="JdbcDataSource" driver="com.mysql.cj.jdbc.Driver" url="jdbc:mysql://localhost:3306/itripdb?characterEncoding=utf8&useSSL=false&serverTimezone=UTC" user="root" password="root"/> <document> <entity name="areaDic" pk="id" query="select * from itrip" deltaImportQuery="select * from itrip where id='${dih.delta.id}'" deltaQuery="select * from itrip where modifyDate > '${dih.last_index_time}'"> <filed name="id" column="id"/> <filed name="name" column="name"/> ... </entity> </document> </dataConfig>配置managed-schema文件,映射到solr中的字段
<!--指定主键--> <uniqueKey>id</uniqueKey> <!--映射从数据库查找出的字段--> <field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="name" type="string" indexed="true" stored="true"/> ...solr控制台引入数据
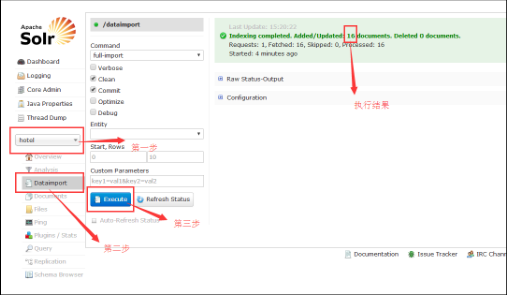
- 查询数据
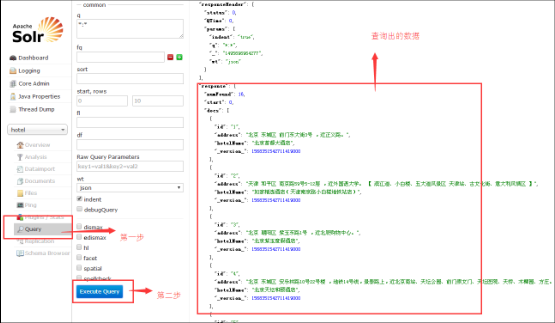
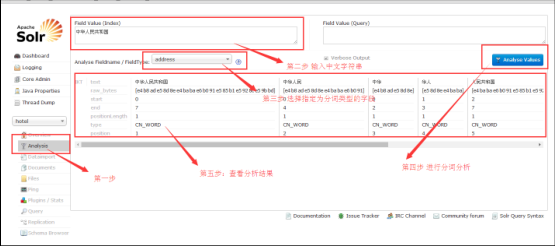
配置分词器
下载新版本ik-analyzer-8.2.0.jar放入server/solr-webapp/webapp/WEB-INF/lib下
配置managed-schema文件
<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/> <analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType> <!--修改其中需要分词的字段的type="分词的type" indexed=true--> <field name="name" type="text_ik" indexed="true" stored="true"/> <!--多字段分词--> <field name="keyword" type="text_ik" indexed="true" stored="true" multiValued="true"/> <copyField source="name" dest="keyword"/> <copyField source="address" dest="keyword" />其他几种分词方式可以查看官方文档